Amazon Lightsailで格安のVPNサーバーを構築してみた
最近Clubhouse流行ってますよね。 そんなClubhouseですが、最近利用者が増えて日本だと夜に接続するとサーバー落ちが頻発するようになりました。
そこでエンジニアがサーバー落ちを防ぐために何をすべきか議論をしている様子を見ていると、
「VPNで海外に接続してみたらどうじゃろ」
という話が出てきました。
なるほど、みんながつないでアクセスを集中しているネットワークに接続しないようにすればいいんですね。
とはいえわざわざVPNのサービスをこのためだけに契約するのもアホらしいですし、中にはEC2で構築してみたという話も出てきました。
エンジニアならAWS使ってVPNサーバー立てたいなとは思いますが、EC2はネットワークのセットアップとか面倒くさそうです。
というわけで今回はAmazon Lightsailを使って簡単に格安でVPNサーバーを立ててみます。
Amazon Lightsailとは?
AWSが提供するVPS(Virtual Private Server)サービスです。
一番安いとなんとたった月額3.5ドルで使うことができるらしいです。
そしてEC2と違いストレージやネットワークなどをパッケージされていることが特徴です。
構築してみた
インスタンスを立てる
まずはAWSにログインします。(アカウント登録してない方はそこからやりましょう)
コンソール画面の検索欄で「lightsail」と打ち込んでlightsailをさがして起動します。

「インスタンスの作成」をクリックします。

インスタンスロケーションをアメリカかイギリスあたりで設定しておきます。
そうなってない場合は「AWSリージョンとアベイラビリティゾーンの変更」をクリックします。

リージョンの選択画面を開いたらリージョンを選択します。 今回はオレゴンを選択します。

インスタンスイメージの選択します。 プラットフォームは「Linux / Unix」、設計図は「OSのみ→Debian9系」を選択します。

インスタンスの初回起動時にVPN実行するスクリプトを設定します。
「起動スクリプトの追加」をクリックします。

コードを入力する欄が表示されるので、以下のスクリプトをコピペします。
インスタンスプランはおそらく3.5ドルのプランが選択されていると思います。

インスタンス名は任意のもので設定します。
その後、「インスタンスの作成」をクリックします。

用意したインスタンスがしばらくして「実行中」と表示されれば無事にインスタンスが立ち上がりました。

静的IPを割り当てる
ネットワーキングタブを選択し、「静的IPの作成」をクリックします。
インスタンスにアタッチされていれば無料で使うことができます。

静的IPを先程作成したインスタンスへアタッチします。
アタッチを完了し、パブリックIPアドレスが表示されたら割当は完了です。

ポートを公開する
インスタンスの管理画面を開き、「ネットワーキング」タブを選択します。
下の方にスクロールしてファイヤーウォールのルールとしてUDP:514とTCP:114を設定します。

デフォルトのパスワードの確認
Lightsailのトップページに戻り、インスタンスのターミナルアイコンをクリックしてブラウザのターミナルを立ち上げます。

sudo /vpn/pritunl default-passwordでVPN管理画面のパスワードを確認します。

pritunlにログイン
https://[設定した静的パブリックIPアドレス]:114/を開き、先程コマンドで確認したユーザー名、パスワードを入れます。
開くときに警告が出ると思いますが無視してアクセスしましょう。

ログインしたらパスワードを変更します。

ユーザーの設定
Usersタブを選択して、Organizationを設定します。

任意のユーザー名、PINを設定します。

サーバーの作成
Serversタブを選択して、Add Serverをクリックします。

任意のサーバー名を設定します。
ポート番号は514、プロトコルはudpとします。

先ほど作成したOrganizationとアタッチしてサーバーを起動させます。

コンソールにログが表示されたらサーバーは起動できています。

設定ファイルをダウンロード
Usersタブを選択して、「Get temporary profile link」をクリックします。

ZIPファイルのダウンロードリンクにあるダウンロードアイコンをクリックします。

ダウンロードしたら展開して、設定ファイルをiPhoneで参照できるようにストレージサービスにアップロードします。
Google Driveにアップロードします。
iPhoneに接続する
Googleドライブアプリを開いて先程保存したファイルの詳細を開いて、「アプリで開く」をタップします。

メニューからOpenVPNを選択します。

OpenVPNが開いたらインポートしたファイルが表示されるので「Add」を選択します。

Usersで設定したユーザー名を入力し、ADDをタップしてVPNの設定を許可します。

Profileを有効にしたらpritunlの初回ログインで設定したパスワードを入力します。

ユーザー設定のときに設定したPINを入力します。

無事に接続できました。 いい感じですね👍

検証
といいたいところですが、このブログを書きながらやっていたらそんなにサーバーが落ちず、普通に音声が聞こえてました。
せっかく、用意したんですけどねw。
でも一応ネットワークのテストをやってみた結果、速度的にはそんなに悪くなかったです。
まぁ1台しかつなげてませんからねw。

PyTorchで学習したモデルをOpenCVで使ってみる
前回はPyTorchでマスクを付けている人を分類するモデルを作りました。
学習させたモデルをOpen CVで使ってみたいと思うのですが、毎回PyTorchを使うのは面倒なのでOpen CVだけでモデルを使う方法を試してみました。
モデルの変換
学習したモデルはPTHで保存できますが、これだと毎回PyTorchを呼び出す必要があります。
そこでモデルをOpen CVで使うためにOpen CVのDNNモジュールに対応しているONNX形式のモデルに変換する必要があります。
PyTorchではtorch.onnx.exportを使えば学習したモデルを簡単にONNX形式で保存できます。
また、Open CVのDNNモジュールを使う場合は、CPUを使うことが多いのでGPUで学習していた場合は念の為モデルをCPU向けに変換します。
これを踏まえて前回のモデルをONNXで変換する場合は以下の通りになります。
torch.onnx.export(model.to('cpu'), torch.randn(1, 3, 224, 224) , "face_mask_detector.onnx")
これで汎用性のあるモデルができました。
モデルを使う
あとはDNNモジュールを使って以下のようにモデルを呼び出せば使えます。
faceMaskNet = cv2.dnn.readNetFromONNX("face_mask_detector.onnx")
PyTorchでマスクしている人を分類してみた
これまでPythonをメインの言語としてプライベートで開発をしていましたが、だいたいWebアプリやIoT系の開発がメインになってしまい、機械学習やDeepLearningは最初のチュートリアルをちょっと触った程度で終わっていました。 Pythonやっててそれはさすがにまずいと思い、自分でDeeplearningで何か実装してみようと思っていました。 そこで今回はマスクを付けている人をPyTorchで分類するモデルを作ってみようと思います。
データセット
まず肝心なデータセットの用意をします。 それぞれ以下のサイトから入手しました。
cabani/MaskedFace-Net - マスクをつけた顔画像のデータセットを取得
Flickr-Faces-HQ Dataset (FFHQ) - マスクをつけていない顔画像のデータセットを取得(↑のデータセットはこのデータセットをベースにマスクをつけているっぽい)
Datasetクラスを作る
PyTorchでは自前のデータセットを扱うにはDatasetクラスを用意する必要がありますが、用意したデータセットを以下のディレクトリ構成で保存すれば、PyTorchのImageFolderを使うことができます。
dataディレクトリを参照することで各クラスのデータセットを取り込みます。
data ├─without_mask └─with_mask
データセットをTensor型に変換するtransformを合わせると以下のようにDatasetクラスを定義できます。
from torchvision import transforms from torchvision.datasets import ImageFolder # データセットの読み込み data_transforms = { 'train': transforms.Compose([ transforms.Resize(size=(224,224)), transforms.RandomRotation(degrees=15), transforms.ColorJitter(), transforms.RandomHorizontalFlip(), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]), 'val': transforms.Compose([ transforms.Resize(size=(224,224)), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]), } dataset = ImageFolder("data", data_transforms['train']) dataset.class_to_idx
dataset.class_to_idxでクラス名、IDの一覧を辞書で確認できます。
以下のようにクラス名、IDが割り振られていたらOKです。
{'with_mask': 0, 'without_mask': 1}
読み込んだデータを訓練用、評価用でそれぞれ分けます。 (訓練用8割、評価用2割)
# 訓練用、評価用にデータを分ける all_size = len(dataset) train_size = int(0.8 * all_size) val_size = all_size - train_size dataset_size = {"train":train_size, "val":val_size} train_data, val_data = random_split(dataset, [train_size, val_size])
DataLoaderの定義とデータの中身の確認
次にDataLoaderを定義します。
# DataLoaderを定義 batch_size = 60 train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True) val_loader = DataLoader(val_data, batch_size=batch_size, shuffle=False) dataloaders = {'train':train_loader, 'val':val_loader}
ここで読み込んだデータの中身を確認します。
ただデータ量が多いので、torchvision.utils.make_grid(images, nrow=10)を使って表示数を絞り込みます。
データの中身を見るときにはmatplotlibをつかいます。
dataiter = iter(dataloaders['train']) images, labels = dataiter.next() # Make a grid from batch out = torchvision.utils.make_grid(images, nrow=10) plt.imshow(out.permute(1, 2, 0))
実行するとデータセットの中から無作為に画像データを選び、その画像を出力します。

モデルの読み込み
torch.hub.loadを使うとトレーニング済みのモデルを読み込むことができます。
今回はこれを使ってMobileNetV2を読み込みたいと思います。
Model = torch.hub.load('pytorch/vision:v0.6.0', 'mobilenet_v2', pretrained=True)
転移学習
このモデルはすでに既存のデータで学習しているため、今回用意したデータを学習させるためには転移学習を行います。 以下のようにパラメータを取り出して、各層をフリーズさせます。
for param in Model.parameters(): param.requires_grad = False
ここで今回用意したデータを学習させるために、最終層のネットワークを上書きします。
# 今回の学習用に最終層のネットワークを上書き Model.classifier[1] = nn.Sequential( nn.Linear(1280, 256), nn.ReLU(), nn.Linear(256, 128), nn.ReLU(), nn.Dropout(0.4), nn.Linear(128, 64), nn.ReLU(), nn.Linear(64, 32), nn.ReLU(), nn.Dropout(0.4), nn.Linear(32, 2), nn.LogSoftmax(dim=1))
ロス関数とoptimizerを定義
cross-emtropyとSGDを定義します。
criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
トレーニング
用意したネットワークとotimizerを使ってトレーニングを行います。
for epoch in range(EPOCH): for phase in ['train', 'val']: if phase == 'train': model.train() else: model.eval() running_loss = 0.0 running_corrects = 0 for inputs, labels in dataloaders[phase]: inputs = inputs.to(device) labels = labels.to(device) with torch.set_grad_enabled(phase == 'train'): outputs = model(inputs) _, preds = torch.max(outputs, 1) loss = criterion(outputs, labels) # backward + optimize only if in training phase if phase == 'train': optimizer.zero_grad() loss.backward() optimizer.step() running_loss += loss.item() * inputs.size(0) correct = torch.eq(torch.max(F.softmax(outputs, dim=1), dim=1)[1], labels).view(-1) running_corrects += torch.sum(correct).item() epoch_loss = running_loss / dataset_size[phase] epoch_acc = running_corrects / dataset_size[phase] loss_dict[phase].append(epoch_loss) acc_dict[phase].append(epoch_acc) print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc)) if phase == 'val' and epoch_loss<0.005: best_loss = epoch_loss best_acc = epoch_acc best_model_wts = copy.deepcopy(model.state_dict()) if (epoch+1)%5 == 0:#5回に1回エポックを表示 print('Epoch {}/{}'.format(epoch+1, EPOCH)) print('-' * 10)
モデルの保存
トレーニングが終わったモデルを保存します。 Pytorchで保存したモデルを呼び出すようにしたいときには以下の1行で完了します。
torch.save(net.state_dict(),"detector/face_mask_detector.pth")
失敗談
ここで素人ならでは(?)の失敗談をまとめてみます。
学習結果が発散してる
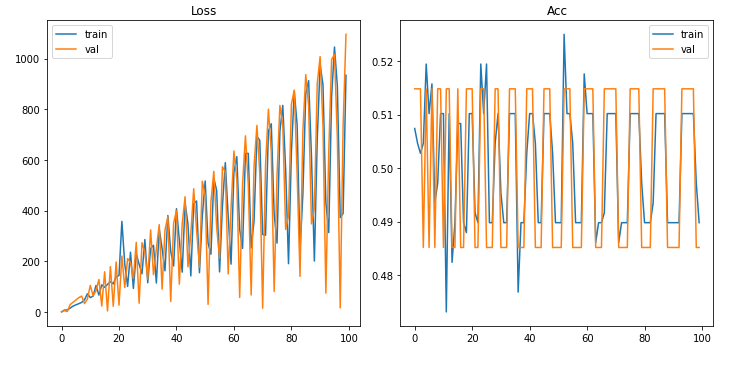
最初に学習をかけたときにどういうわけか学習結果が波打つように変化したグラフが出力されました。
なんかの信号入力をグラフにしたのかと思うぐらいですw。
これは逆伝搬したときに勾配が更新されることが原因のようです。
これによって、すでに存在している勾配があるとそこに勝手に追加されてしまうため、lossのグラフが発散してしまったようです。
そこでトレーニングの段階でパラメータの更新が終わったらoptimizer.zero_grad()を行うことで勾配情報がリセットされて前のトレーニングの結果に引きずられることがなくなります。
↓こちらの記事が参考になりました
中途半端な学習結果

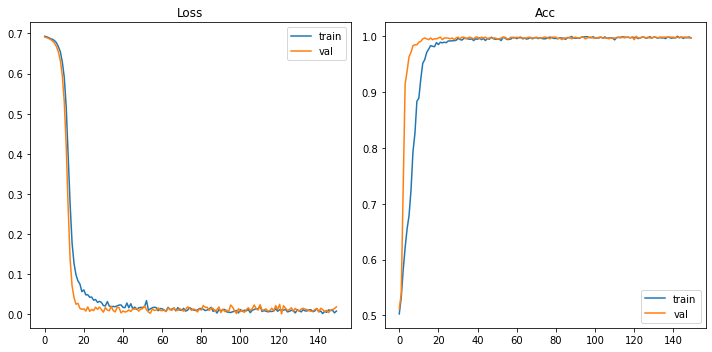
optimizer.zero_grad()を入れてなんとか理想に近いグラフはできましたが、ノイズも混ざって中途半端なグラフになりました。
Validに関しては1に到達しているものもあります(1に到達せず収束するのが理想)。
これはデータ数を増やせば解決します。
各クラス1600枚ほど用意するとこんな感じで激しいノイズを起こさずにきれいに収束したグラフをできました。
ソースコード
今回作ったソースコードはこちらのGithubレポジトリで公開しています。
まとめ
今回は今までチュートリアル止まりで終わっていたディープラーニングを自分で実装してみました。 難しそうに見えたものもライブラリの力で簡単に実装できるのはいいなと思いました。 特にPytorchは導入もシンプルでドキュメントも割と丁寧なのでこれからどんどん使いこなしたいですね。
Node-REDでTelloを動かすためのノードを作って公開してみた
この記事は個人開発 Advent Calendar 202013日目の記事です。
これまでNode-REDを使ってきましたが、どこか物足りなさを感じていました。
それは自分で自作ノードを作ってみたいということです。
最近ではいろんな人達がノードを公開しているので、探せばやりたいことを実現できると思ってそこで止まっていました。
それで話変わりまして、数ヶ月前にTelloを衝動買いして早速触ったことも無いScratchを使ってTelloを制御してみました。
今更だけどScratchでTello動かしてみた。今じゃこういうの目新しさないけどやっぱり動くの見ると楽しい!
— K.Miura (@k_miura_io) September 20, 2020
しかも動かすときめちゃめちゃハマった分喜びも倍増(ハードウェアのデバッグは辛い pic.twitter.com/dCy8zoIbGS
これを動かしていたときにいろいろ思うことがありました。
- Scratch動かしてるけど実際はローカルで立てたNode.jsにコマンドをHTTPリクエストしてる→準備がめんどくさい
- Scratch2.0で動かす必要がある→Macでは起動自体めんどくさい
- 同じNode.jsならNode-REDで動かしたほうが楽そう(小並感)
そこで、TelloをNode-REDで動かす事例を調べてみるとデフォルトのUDPノードを使った事例が紹介されていました。
ありものを使うのもいいですが、やはりScratchのときのような手軽さを追求したいという気持ちが湧いてきました。
というわけでTelloをNode-REDで簡単に操作するためのノードを作ってみようと思いました。
要件定義
特に明確にしたわけではありませんが、Node-REDで使えるようにするなら外せない条件をリストアップしてみました。
- Scratch版で提供している基本動作(離陸、着陸、上下左右など)は最低限実装する
- 実行結果をmsg.payloadで出力する
- ステータス(バッテリー残量、温度など)を出力する機能も実装する
これだけ入れておけば、ただのScratchを移植しただけではない、Node-REDを生かしたものになるんじゃないかなと思います。
公開したノード
node-red-contrib-telloという名前で公開しています。
READMEは英語ですが、Node-REDを使ったことある方なら多分雰囲気で動かせると思います。
このブログでも実装面の解説をしているので、なんとなく使い方が分かると思います
実装
細かい実装については、以下のGithubレポジトリを眺めてもらうといいですが、ここではポイントを絞ってお話します。
基本動作
このノードではすべて裏側でUDP送信を行うsendCommand関数を用意しています。
この辺はScratchのノードを動かすときに使っていたNode.jsのコードを参考にしています。
離陸と着陸
これはべつに値が変化することでも無いので、それぞれつなげるだけ実行するようにしてみました。
値の受け取り(数値)
距離や角度を指定するノードではノードの設定で数値を指定することはできますが、入力欄を空欄にするとmsg.payloadで受け取った値をコマンドの入力として使います。
こうすることで例えばセンサーの値を受け取ってそれをTelloに反映するということをやることもできます。(そのうちサンプルを用意します)

値の受け取り(セレクトボックス)
セレクトボックスを使ったノード(flipノードなど)はHTMLのセレクトボックスを使っているので値はvalue属性で担保しているので、Scratchのときよりもメニューが見やすくなったと思います。
ちなみにセレクトボックスの値は必ずどれか選択するようにしています。(これをmsg.payloadで受け取れるようにしたら、ノードのゲシュタルト崩壊してしまう…)

stateノード
stateノード以外は挙動がほぼ同じなので、基本的にはフロントのHTMLを修正したりコマンドを送信する前の処理の修正してあとはコピペするだけでそんなに時間はかかりません。
ところが、このstateノードについては一番実装に苦戦しました。
というのもUDPはHTTPリクエストと違って受信と送信は一方通行になっています。
そのためUDPで受け取った値はグローバル変数に格納しています。
そのときにstateコマンド(ケツに?を入れるコマンド)を実行するとその返答はコマンド送信を完了したときに受け取るOKの後に連続でstateコマンドで聞いた値を返すようになっています。
これをどうやってノードを使って返そうか悩みましたが、単純にPromiseを使って時間差でコードを実行するようにして最終的にstateコマンドの結果を取れるようにしてみました。
JavaScriptって非同期のせいかスリープの処理にもクセがあって毎回実装辛いですね…
node.on("input", function (msg) { Promise.resolve() .then(function () { sendCommand("command"); }) .then(function () { return new Promise(function (resolve, reject) { setTimeout(function () { sendCommand(node.command); resolve(); }, 500); }); }) .then(function () { return new Promise(function (resolve, reject) { setTimeout(function () { RED.log.info("Result state command: " + telloState); msg.payload = telloState; node.send(msg); resolve(); }, 500); }); }); });
だいぶ力技ですが、これでちゃんと値が取れるようになりました。
トラブルシューティング
- レスポンスが出力されず、文字列が空
- Telloの動作が不安定な可能性があります。Telloを再起動するか、バッテリーをフル充電しましょう
- ノードに値を入れたのに動作しない
No invalid imuと出る場合はimuセンサーが機能していないことがあります。Telloを再起動かバッテリーをフル充電しましょう。- 本体を触って熱かったら電源を落として冷めるまで待ちましょう。
- そもそもtakeoffしない
- Node-REDがTelloと接続できていない可能性があります。TelloとPCの接続を確認して問題なさそうでしたら、Node-REDを再起動して試してみましょう。
まとめ
今回は僕が初めてリリースしたNode-REDライブラリの話をしました。
最初は難しそうだったので、なかなか作る機会がなかったのですが、多少JavaScriptがわかっていればそんなに実装に困ることはなくて意外と簡単にできました。
改善点がありましたらレポジトリへのissueやPR大歓迎です!
Node-REDのobnizノードを使ってobnizを動かしてみた
Node-RED Con Tokyo 2020に参加してきました。
昨年も開催されたNode-RED UG Japan主催のカンファレンスで中身の濃い知見を得られました。
この中のobnizのセッションの中で、カンファレンスの前日にリリースしたばかりだというobnizノードの紹介がありました。
おーできたてほやほや#nodered #noderedjp pic.twitter.com/Y8NN00DGeY
— K.Miura (@k_miura_io) 2020年10月10日
その昔、ハッカソンでNode-REDを使ってobnizから送られてくるセンサの値を受け取るということに挑戦したのですが、開発にかなり苦戦した覚えがあります。
おまけに初めてobniz触ったこともあり、いまいち使い勝手が分からなかったんですよねw。
そんなobnizをNode-REDから操作できるノードが公式でリリースされたのはいいですね。
というわけで今回はこのobnizノードを使ってIBM CloudのNode-REDからobnizを操作してみたいと思います。
ちなみにNode-REDの環境を用意できれば動作環境は何でもいいと思います。 環境構築方法はNode-RED UG Japanのドキュメントが参考になります。
インストール
まずはインストールしてみます。インストール方法はここにあったので、この通りにやってみます。
Node-REDを立ち上げたら右上のメニューから「パレットの管理」を選択します

「ノードを選択」タブを選択して検索窓にobnizと検索すれば「node-red-contrib-obniz」が1件ヒットすると思うので、「ノードを追加」をクリックして、インストールします。

途中でこんなダイアログが出ますが、気にせず「追加」をクリックします。

パレットの管理画面を閉じて、左側のノードの一覧にこのようにノードが出てきたらインストールは完了です。

とりあえず動かしてみた
とりあえずobniz のディスプレイに何か文字を表示するフローを作ってみます。
フローはこんな感じです。injectノードから適当な文字列を送ると、obnizのディスプレイにその文字が表示されます。

ここでよく見るとobnizノードの右上に赤い三角がついてますね。
obnizノードを使うにはお使いのobnizのデバイス情報を登録する必要があります。
というわけで接続したobnizのfunctionノードをダブルクリックしてノードの編集画面を開きます。 「新規にobnizを追加」の横にある鉛筆マークをクリックして、obnizの接続情報を追加しましょう。

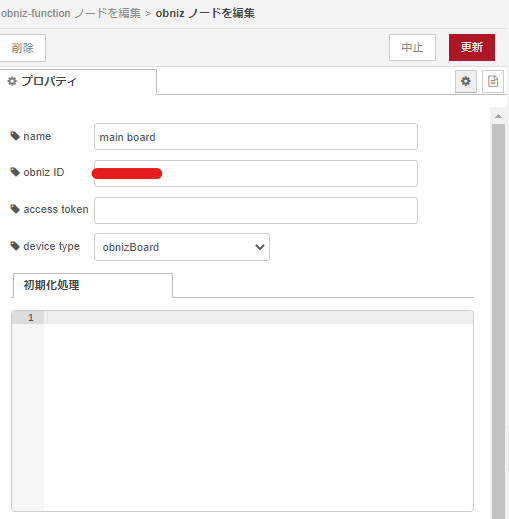
プロパティの画面では色々設定する必要があります。設定項目としては以下の通りです。
| 項目 | 詳細 |
|---|---|
| obniz ID | obnizをWifiに接続すると表示するID |
| access token | obnizの開発者コンソールで取得するトークン (設定していない場合は空欄でOK) |
| device type | デバイスの種類 |
一通り設定すると、以下のようになります。僕はアクセストークンを設定していないのでaccess tokenは空欄になっています。
これで「更新」をクリックするとノードの編集画面に戻ります。
続いて「コード」の欄にデバイス操作を行うためのコードを書きます。
コードについては公式ドキュメントのコードを書くと操作できます。
これを元にコードには、以下の2行を書きます。
obniz.display.clear(); obniz.display.print(msg.payload);
1行目のobniz.display.clear();をやらないとディスプレイの内容が上書きされて表示がぐちゃぐちゃになるので入れておいたほうがいいです。
2行目のobniz.display.print();の引数で指定した文字列をディスプレイに表示させます。
今回はinjectノードからの入力を表示するため、msg.payloadを引数にしています。
コードの記入を終えたら「完了」を押して、編集を終えます。

あとは右上の「デプロイ」ボタンをクリックしてデプロイして、以下のようにconnectedが表示されればobnizとNode-REDは正常に接続されています。

injectノードの左側のボタンをクリックして、接続されたobnizのディスプレイに文字列が表示されたら成功です。

入力もやってみる
せっかくなので、もう片方のrepeatノードの方も試してみます。
このノードはobnizから何かしらのインプットがあったときに使えるノードです。
ここでは、obnizの上についているスイッチで何か操作すると、デバッグにその操作内容が表示するというフローを作ってみます。
フローとしては以下の通りです。

まずは、obniz repeatノードをダブルクリックして編集画面を開きます。先程設定したobnizのデバイスが選択されていたらデバイスの設定は不要です。
もし何も表示されていない場合は、セレクトボックスから先程登録したデバイスを選択します。
このノードは一定の間隔でコードを実行する仕組みなので、以下のコードをコード欄に貼り付けます。
var state = await obniz.switch.getWait(); msg.payload = state; return msg;
こちらもNode-REDで標準で使えるfunctionノードの使い方と同じになるので、実行結果を出力するには、最後に
return msg;を書く必要があります。
次のswitchノードは何も入力が無かったときにnoneが出力されるので、none以外の出力を表示するために条件分岐を入れています。

フローを作成してデプロイを行うと、以下のようにobinizのスイッチの状態(none以外)がデバッグ画面に表示されます。

今回のフロー
[{"id":"523da830.10ea08","type":"tab","label":"obniz Control","disabled":false,"info":""},{"id":"fcbde703.c35d28","type":"obniz-function","z":"523da830.10ea08","obniz":"a8808e2f.d98e9","name":"","code":"obniz.display.clear();\nobniz.display.print(msg.payload);","x":560,"y":320,"wires":[["b1dcc84e.b9b438"]]},{"id":"bb4f92aa.2cab","type":"inject","z":"523da830.10ea08","name":"","topic":"","payload":"Hello World!","payloadType":"str","repeat":"","crontab":"","once":false,"onceDelay":0.1,"x":270,"y":300,"wires":[["fcbde703.c35d28"]]},{"id":"885dcb9f.d6ddf8","type":"inject","z":"523da830.10ea08","name":"","topic":"","payload":"Goodbye","payloadType":"str","repeat":"","crontab":"","once":false,"onceDelay":0.1,"x":260,"y":360,"wires":[["fcbde703.c35d28"]]},{"id":"b1dcc84e.b9b438","type":"debug","z":"523da830.10ea08","name":"","active":true,"tosidebar":true,"console":false,"tostatus":false,"complete":"false","x":820,"y":320,"wires":[]},{"id":"ff8bb61.4f49a48","type":"obniz-repeat","z":"523da830.10ea08","obniz":"a8808e2f.d98e9","name":"","interval":"1000","code":"var state = await obniz.switch.getWait();\r\nmsg.payload = state;\r\n\r\nreturn msg","x":240,"y":480,"wires":[["488a94d0.8dda7c"]]},{"id":"ca3a09ac.aed6f8","type":"debug","z":"523da830.10ea08","name":"","active":true,"tosidebar":true,"console":false,"tostatus":false,"complete":"false","x":830,"y":480,"wires":[]},{"id":"488a94d0.8dda7c","type":"switch","z":"523da830.10ea08","name":"","property":"payload","propertyType":"msg","rules":[{"t":"neq","v":"none","vt":"str"}],"checkall":"true","repair":false,"outputs":1,"x":510,"y":480,"wires":[["ca3a09ac.aed6f8"]]},{"id":"a8808e2f.d98e9","type":"obniz","z":"","obnizId":"","deviceType":"obnizboard","name":"main board","accessToken":"","code":""}]
まとめ
今回はNode-REDでobnizを動かしてみました。
obnizとのやり取りがよりシンプルになってとてもいいと思いました。
最初コードの書き方がよく分からず戸惑いましたが、functionノードを使っていたらその感覚でobniz.jsのコードを書くだけになるので、慣れれば何でもできそうな気がします。
これでNode-REDでobnizを動かしていたときのつらみが解消される気がします。
オレオレkivyチュートリアル~その2 ボタンを実装~
前回はkivyをパソコンに導入して、アプリを作成するところを紹介しました。
今回はボタンを押したら文字を変更するアプリを実装してみます。kivyのインストールがまだの場合は前回紹介しているセットアップを終えてから続きを進めてもらえるといいと思います。
ボタンの実装
それでは、前回のコードから修正を加えてボタンをとりあえず実装してみます。
コードは以下になります。
前回との違いはfrom kivy.uix.label import Labelがfrom kivy.uix.button import Buttonに変更されて、sampleApp.buildの戻り値がButtonに変更されています。
from kivy.app import App
from kivy.uix.button import Button
class sampleApp(App):
def build(self):
return Button(text='Hello World!')
if __name__ == '__main__':
sampleApp().run()
実行すると、以下のようにウィンドウ全体にボタンが表示されます。ボタンをクリックすると画面がフラッシュしたような挙動をします。

何かアクションを加えてみる
それでは次にボタンを押したときのアクションを足してみます。
ボタンを押したら文字列がコンソールに出力されるようにします。
というわけでsampleAppクラスにメソッドを追加して以下のコードを動かしてみます。
from kivy.app import App
from kivy.uix.button import Button
class sampleApp(App):
def build(self):
return Button(on_press=self.pressed, text='Hello World!')
def pressed(self, btn):
print('pressed')
if __name__ == '__main__':
sampleApp().run()
実行するとボタンを押したときにコンソール画面にpressedメソッドで指定した文字列が出力されます。

BoxLayoutを使ってみる
ここまでは画面いっぱいに一つのボタンを用意しましたが、これでは他のUIを組み込むことができません。
そこで、BoxLayoutを使って画面に複数のUIを実装してみたいと思います。
BoxLayoutを使えば水平・垂直方向にUIを配置することができるようになります。
BoxLayout()の引数のorientationで配置する方向を設定することができます。(vertical:垂直方向、horizontal:水平方向)
また、add_widget()メソッドを使って、UIを配置することになります。
前回使ったラベルと組み合わせたコードが以下のとおりです。
from kivy.app import App
from kivy.uix.button import Button
from kivy.uix.label import Label
from kivy.uix.boxlayout import BoxLayout
class sampleApp(App):
def build(self):
layout = BoxLayout(orientation='vertical')
self.lb = Label(text='Hello World!')
self.bt = Button(on_press=self.pressed, text='Push')
layout.add_widget(self.lb)
layout.add_widget(self.bt)
return layout
def pressed(self, btn):
self.lb.text = 'pressed'
if __name__ == '__main__':
sampleApp().run()
sampleApp.pressedのアクションをprint関数からラベルの表示を変更するテキストに変更しました。
実行すると、以下のようにボタンを押すとラベルのテキストが変更されます。

ボタンを押しているときだけテキストを変更する
先程までの実装だとボタンを押したらテキストは変更されたままになるので、今度はボタンを押している間だけテキストが変更されるようにしてみます。
やり方としてはButton()オブジェクトのオプションでon_pressを指定したときと同様に、on_releaseにメソッドを指定するとボタンを離したときのメソッドを指定します。
self.bt = Button(on_press=self.pressed, on_release=self.released, text='Push')
また、sampleAppクラスに新たに以下のメソッドを追加します。
def released(self, btn):
self.lb.text = 'Hello World!'
実行すると押している間だけ、ラベルのテキストが変更されてボタンを離すと元のテキストに戻るようになります。

まとめ
今回はボタンを装備して、そのボタンに対して何かアクションを付ける方法を紹介しました。
ここまでのことをやれば例えばRaspberry Piを使ってGPIOの操作を実装することもできます。
次回はもっと自由自在にUIのレイアウトができるkv languageについて紹介します。
「freee / IBM Cloud / LINE API アプリ開発勉強会」に登壇してみた&サンプルアプリの補足
freeeさんの主催のアプリ開発勉強会に登壇しました。
このイベントは只今絶賛開催中の「freeeアプリコンテスト」関連のイベントになっており、ここではfreeeのAPIを使ったアプリ開発についてサンプルアプリを交えて紹介しました。
今回は僕のパートで紹介したアプリについての簡単な解説とセッション中に話せなかった補足的なお話をします。 個人的にはfreeeのAPIの仕様に苦しめられて作るのにめっちゃ時間がかかりましたが、反応はそこそこでやってよかったと思います。 (欲を言えばライブデモをやったので、その反応がもっと欲しかったw)
今回紹介したアプリは僕のGithubのレポジトリにソースコードが出ているので、中身についてはそちらを御覧ください。
今回作ったアプリ
freeeのアプリアワードのページのなかで紹介されている「みんなの困り事」の中から
- 経費精算が大変
- 打刻忘れが多い
といったことを手元のLINE botを解決してみましょうというものです。
実際の動作はこちらからご覧いただけます。
開発環境
- Python
- Flask
- ngrok or heroku
以前の記事で紹介した動作環境とほぼ一緒で、ローカルでngrokを使うこともできますし、herokuにデプロイできるようにProcfileも用意しています。
今回のソースコードを見てもらうと.envで設定する環境変数がやたら多いですw。 というわけでこの補足記事では各環境変数をどこから持ってくればいいかを紹介します。
- 今回作ったアプリ
- 開発環境
- LINE Developersから取得する変数
- Clova OCR
- Cloudant
- freeeの事業所ID
- IBM Cloud Functions
- 環境変数の設定
- まとめ
LINE Developersから取得する変数
Messaging API
CHANNEL_ACCESS_TOKENとCHANNEL_SECRETは、Messaging APIのチャネルから取得します。
また、リッチメニューのIDATTEND_MENU_IDとON_WORK_MENU_IDはREADMEのリッチメニューの登録でAPIを使うと出力されるリッチメニューIDをそれぞれ設定します。
ATTEND_MENU_IDは出勤時に表示させるリッチメニューIDで、ON_WORK_MENU_IDは業務時間中に表示するリッチメニューIDです。
LIFF
REGIST_LIFF_IDとFIX_TIME_LIFF_IDはLINEログインチャネルを立ててLIFFを作成すると表示されているLIFF IDをコピーします。
管理がしやすいので、同じチャネルにLIFFを2つ作成してOKです。また設定するエンドポイントは以下の通りです。
REGIST_LIFF_ID:【アプリのURL】/registFIX_TIME_LIFF_ID:【アプリのURL】/fix_time
このときチャネルはユーザIDを共有するため、Messaging APIを立てたときと同じプロバイダーで立てます。
Clova OCR
OCR_API_URLとOCR_API_KEYについてはLINE Developersでは提供されていないサービスで別途用意する必要があります。
今回のアワードの参加者限定で無料で公開されるので、詳しくは以下の記事からご覧いただければと思います。
APIトークンとURLについては申請すると認証情報がもらえると思うので、もらったときにそれぞれ変数を設定しましょう。
Cloudant
認証情報
CloudantはIBM CloudでCloudantのリソースを作成しておきます。ちなみにNode-REDを使っている方はすでにCloudantのリソースがあるのでそちらを使ってもらってOKです。
リソースを開いたらサービス資格情報タブを選択して、新規資格情報を作成をクリックします。
役割の項目は「管理者」を選択した状態で追加をクリックして作成します。

ここで生成されたURL、ユーザー名、パスワードをCLOUDANT_URL、CLOUDANT_USERNAMEそしてCLOUDANT_PASSWORDに設定します。
データベースの設定
TOKEN_DOC_IDについては管理タブをクリックして、Launch Dashboardを開くとCloudantのダッシュボードが開きます。
そこから「Create Database」をクリックして、freee_tokensを作成します。同様にログ取り用にlabor_botも作成しておきます。

その後、freee_tokensを開き、Create Documentをクリックしてドキュメントの作成画面が開きます。
このときIDが表示されるのでこのIDを.envのTOKEN_DOC_IDに設定します。
ドキュメントにはこちらで紹介されている、アクセストークンを取得するAPIを実行したときのレスポンスの中身を以下のように追加します。
追加したら、Create Documentをクリックしてデータベースの設定を完了させます。

freeeの事業所ID
COMPANY_IDは先程取得したアクセストークンを使って、事業所IDの一覧を取得するAPIを実行したときのレスポンスに出てくるcompany_idを設定します。
IBM Cloud Functions
ここまで.envファイルに必要な変数を紹介しましたが、更にIBM Cloud Functionsにも追加で変数を設定をすることでfreeeのトークンの自動更新機能を動かすことができます。
こちらを開いて、アクションを作成します。
アクションの作成方法は以下の記事を御覧ください。パラメータ(環境変数)の設定方法も記載しています。
また、使用するコードはレポジトリ内のこちらのコードです。
パラメータは以下の値を設定します。
| Parameter Name | Parameter Value |
|---|---|
| CLIENT_ID | freeeのアプリ管理画面から取得 |
| CLIENT_SECRET | freeeのアプリ管理画面から取得 |
| URL | CloudantのURL |
| PASSWORD | Cloudantのパスワード |
| USERNAME | Cloudantのユーザーネーム |
| TOKEN_DOC_ID | .envに設定したもの |
環境変数の設定
ngrokで動かす時は特に気にする必要はありませんがherokuでデプロイするには.envファイルの環境変数をheroku側に反映させる必要があります。 一つずつやるのはさすがに面倒なので以下のコマンドを.envファイルのあるディレクトリ上で実行すると環境変数をまとめて反映してくれます。
heroku config:push
まとめ
今回はイベントのデモで使ったコードの環境変数の設定について紹介しました。
ただ値を取るだけの話ですが、APIを使う上ではいろんなサービスを行ったり来たりしながらの作業なので自ずといろんなサービスを触って知ることになるので理解も深まると思います。
そして、また次に何かアプリを作りたいときに簡単にアイデアを形にしやすいです。
逆にAPIを作る側になると設計からリリースまでのプロセスがありとても大変なものです。(この話はよしましょうw。)